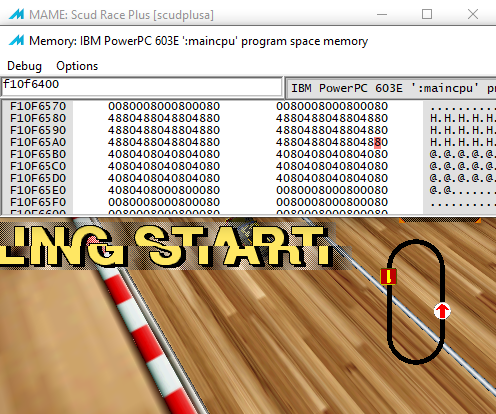
Because drawing is kind of slow on the cpu, and a GPU is a massive SIMD monster that can probably eat more data than you can throw at it. Originally I was thinking about writing a compute shader to do this, because with compute shaders you can write to arbitrary memory locations, but in the end I figured we could do it in a fragment shader.
With older opengl (2.1) really you could only do floating point math on the GPU in the shader. There really was very little integer math other than maybe a loop counter, which might get unrolled anyway.
With gl3+ you can do full integer maths so %^|&& etc with signed and unsigned data types
How do we map the memory to the GPU?
Well in opengl we either get uniform memory or texture memory. The VRAM is way too big to pass as uniform memory to the shader, so must be mapped as a texture. How do we map vram as a texture? Well the bottom part of the memory is exactly 1mb, which we can map to a 512x512 texture (4 bytes per pixel) == 1mb. In order to index the vram texture, we have to generate texture coordinates to map to the memory locations. I use this simple function
- Code: Select all
ivec2 GetVRamCoords(int offset)
{
return ivec2(offset % 512, offset / 512);
}
That essentially maps a 1d to a 2d array of a fixed width/height. The palette data works the same way, but with a different texture. To read the texture i use the texelFetch function, which takes integer coordinates and skips the bilinear/trilinear and other possible filtering modes associated with reading textures.
The shader inputs can map to an array of integer uniform inputs. Uniforms are great because conditional logic based upon inputs can be optimised away because every pixel for the draw call will evaluate to the same logic.
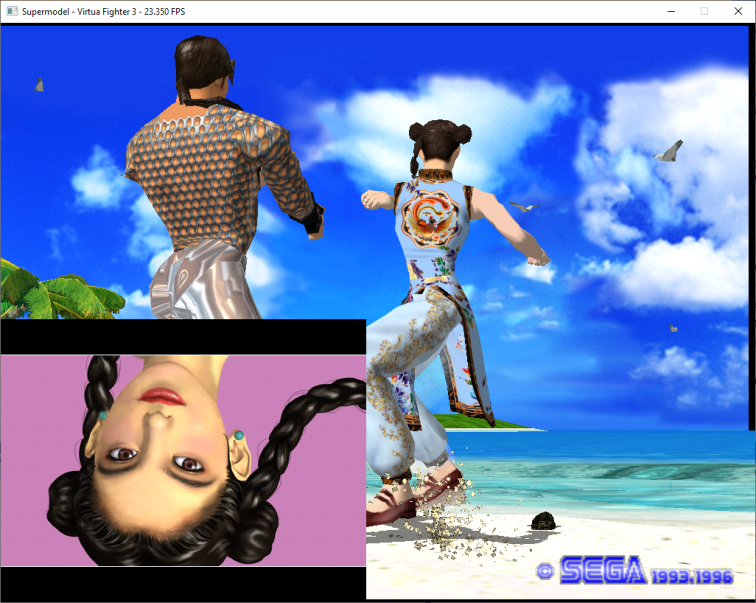
Here is what it looks like. This is drawing drawing like layer 2 directly to the frame buffer in a 496x384 window as a test
This is the shader code
- Code: Select all
// Vertex shader
static const char s_vertexShaderSourceNew[] = R"glsl(
#version 410 core
void main(void)
{
const vec4 vertices[] = vec4[](vec4(-1.0, -1.0, 0.0, 1.0),
vec4(-1.0, 1.0, 0.0, 1.0),
vec4( 1.0, -1.0, 0.0, 1.0),
vec4( 1.0, 1.0, 0.0, 1.0));
gl_Position = vertices[gl_VertexID % 4];
}
)glsl";
// Fragment shader
static const char s_fragmentShaderSourceNew[] = R"glsl(
#version 410 core
//layout(origin_upper_left) in vec4 gl_FragCoord;
// inputs
uniform usampler2D vram; // texture 512x512
uniform usampler2D palette; // texture 128x256 - actual dimensions dont matter too much but we have to stay in the limits of max tex width/height, so can't have 1 giant 1d array
uniform uint regs[32];
uniform int layerNumber;
// outputs
out vec4 fragColor;
ivec2 GetVRamCoords(int offset)
{
return ivec2(offset % 512, offset / 512);
}
ivec2 GetPaletteCoords(int offset)
{
return ivec2(offset % 128, offset / 128);
}
uint GetLineMask(int yCoord)
{
uint shift = (layerNumber<2) ? 16u : 0u; // need to check this, we could be endian swapped so could be wrong
uint maskPolarity = ((layerNumber & 1) > 0) ? 0xFFFFu : 0x0000u;
int index = (0xF7000 / 4) + yCoord;
ivec2 coords = GetVRamCoords(index);
uint mask = ((texelFetch(vram,coords,0).r >> shift) & 0xFFFFu) ^ maskPolarity;
return mask;
}
bool GetPixelMask(int xCoord, int yCoord)
{
uint lineMask = GetLineMask(yCoord);
uint maskTest = 1 << (15-(xCoord/32));
return (lineMask & maskTest) != 0;
}
int GetLineScrollValue(int layerNum, int yCoord)
{
int index = ((0xF6000 + layerNum * 0x400) / 4) + (yCoord /2);
int shift = (yCoord % 2) * 16; // double check this
ivec2 coords = GetVRamCoords(index);
return int((texelFetch(vram,coords,0).r >> shift) & 0xFFFFu);
}
int GetTileNumber(int xCoord, int yCoord, int xScroll, int yScroll)
{
int xIndex = ((xCoord + xScroll) / 8) & 0x3F;
int yIndex = ((yCoord + yScroll) / 8) & 0x3F;
return (yIndex*64) + xIndex;
}
int GetTileData(int layerNum, int tileNumber)
{
int addressBase = (0xF8000 + (layerNum * 0x2000)) / 4;
int offset = tileNumber / 2; // two tiles per 32bit word
int shift = (1 - (tileNumber % 2)) * 16; // triple check this
ivec2 coords = GetVRamCoords(addressBase+offset);
uint data = (texelFetch(vram,coords,0).r >> shift) & 0xFFFFu;
return int(data);
}
int GetVFine(int yCoord, int yScroll)
{
return (yCoord + yScroll) & 7;
}
int GetHFine(int xCoord, int xScroll)
{
return (xCoord + xScroll) & 7;
}
// register data
bool LineScrollMode (int layerNum) { return (regs[0x60/4 + layerNum] & 0x8000) != 0; }
int GetHorizontalScroll(int layerNum) { return int(regs[0x60 / 4 + layerNum] &0x3FFu); }
int GetVerticalScroll (int layerNum) { return int((regs[0x60/4 + layerNum] >> 16) & 0x1FFu); }
int LayerPriority () { return int((regs[0x20/4] >> 8) & 0xFu); }
bool LayerIs4Bit (int layerNum) { return (regs[0x20/4] & (1 << (12 + layerNum))) != 0; }
bool LayerEnabled (int layerNum) { return (regs[0x60/4 + layerNum] & 0x80000000) != 0; }
bool LayerSelected (int layerNum) { return (LayerPriority() & (1 << layerNum)) == 0; }
float Int8ToFloat(uint c)
{
if((c & 0x80u) > 0u) { // this is a bit harder in GLSL. Top bit means negative number, we extend to make 32bit
return float(int(c | 0xFFFFFFu)) / 128.0;
}
else {
return float(c) / 127.0;
}
}
vec4 GetColourOffset(int layerNum, vec4 colour)
{
uint offsetReg = regs[(0x40/4) + layerNum/2];
vec4 c;
c.b = Int8ToFloat((offsetReg >>16) & 0xFFu);
c.g = Int8ToFloat((offsetReg >> 8) & 0xFFu);
c.r = Int8ToFloat((offsetReg >> 0) & 0xFFu);
c.a = 0.0;
colour += c;
return clamp(colour,0.0,1.0); // clamp is probably not needed
}
vec4 Int16ColourToVec3(uint colour)
{
uint alpha = (colour>>15); // top bit is alpha. 1 means clear, 0 opaque
alpha = ~alpha; // invert
alpha = alpha & 0x1u; // mask bit
vec4 c;
c.r = float((colour >> 0 ) & 0x1F) / 31.0;
c.g = float((colour >> 5 ) & 0x1F) / 31.0;
c.b = float((colour >> 10) & 0x1F) / 31.0;
c.a = float(alpha) / 1.0;
c.rgb *= c.a; // multiply by alpha value, this will push transparent to black, no branch needed
return c;
}
vec4 GetColour(int paletteOffset)
{
ivec2 coords = GetPaletteCoords(paletteOffset);
uint colour = texelFetch(palette,coords,0).r;
return Int16ColourToVec3(colour); // each colour is only 16bits, but occupies 32bits
}
vec4 Draw4Bit(int tileData, int hFine, int vFine)
{
// Tile pattern offset: each tile occupies 32 bytes when using 4-bit pixels (offset of tile pattern within VRAM)
int patternOffset = ((tileData & 0x3FFF) << 1) | ((tileData >> 15) & 1);
patternOffset *= 32;
patternOffset /= 4;
// Upper color bits; the lower 4 bits come from the tile pattern
int paletteIndex = tileData & 0x7FF0;
ivec2 coords = GetVRamCoords(patternOffset+vFine);
uint pattern = texelFetch(vram,coords,0).r;
pattern = (pattern >> ((7-hFine)*4)) & 0xFu; // get the pattern for our horizontal value
return GetColour(paletteIndex | int(pattern));
}
vec4 Draw8Bit(int tileData, int hFine, int vFine)
{
// Tile pattern offset: each tile occupies 64 bytes when using 8-bit pixels
int patternOffset = tileData & 0x3FFF;
patternOffset *= 64;
patternOffset /= 4;
// Upper color bits
int paletteIndex = tileData & 0x7F00;
// each read is 4 pixels
int offset = hFine / 4;
ivec2 coords = GetVRamCoords(patternOffset+(vFine*2)+offset); // 8-bit pixels, each line is two words
uint pattern = texelFetch(vram,coords,0).r;
pattern = (pattern >> ((3-(hFine%4))*8)) & 0xFFu; // shift out the bits we want for this pixel
return GetColour(paletteIndex | int(pattern));
}
void main()
{
ivec2 pos = ivec2(gl_FragCoord.xy);
int tileNumber = GetTileNumber(pos.x,pos.y,0,0);
int hFine = GetHFine(pos.x,0);
int vFine = GetVFine(pos.y,0);
int tileData = GetTileData(layerNumber,tileNumber);
if(LayerIs4Bit(layerNumber)) {
fragColor = Draw4Bit(tileData,hFine,vFine);
}
else {
fragColor = Draw8Bit(tileData,hFine,vFine);
}
}
)glsl";
What's left? Well most of the code is pretty much there. I just need to plugin scroll values/masking. Maybe can generate 1 layer of A and A' with a single draw pass?
The colour offsets can also be directly applied in the shader, so no need to pre-calculate these. This will simplify the logic in the tilegen class a lot.
Upsides/Downsides?
Downside is fragment shaders are much harder to debug than cpu side code. Emulating possible querks of the tilegen such as the fact the shift register? is reloaded only 8 pixels might be harder in a fragment shader and might require some ugly logic, as every pixel in the fragment shader is basically independent. Also if we emulated drawing 1 line at a time we would start to lose the speed benefits of doing it on the GPU as each draw call has a cost.
Upside?
So fast might as well be free, at least on a non ghetto gpu from this decade :p